Image: Flickr / Wikimedia Commons / Unsplash
Claude Opus 4.8 Arrives With Stronger Agentic Coding, Dynamic Workflows, and a Cheaper Fast Mode
Anthropic ships Opus 4.8 at the same price as Opus 4.7, with benchmark gains over GPT-5.5, a new multi-agent feature for Claude Code, and a 3x cheaper fast mode.
This article was produced by the AETW editorial team.
Anthropic released Claude Opus 4.8 on May 28, 2026 with stronger coding benchmarks, dynamic workflows for Claude Code that spawn hundreds of parallel subagents, user-level effort controls, and a fast mode that now costs three times less than before.
What changed with Opus 4.8
Anthropic released Claude Opus 4.8 on May 28, 2026, an upgrade to its flagship model that builds on Opus 4.7 with better performance across coding, reasoning, and knowledge work. The launch arrives at the same price as its predecessor - $5 per million input tokens and $25 per million output tokens via the Anthropic Claude API - making it a no-cost switch for teams already running Opus in production.
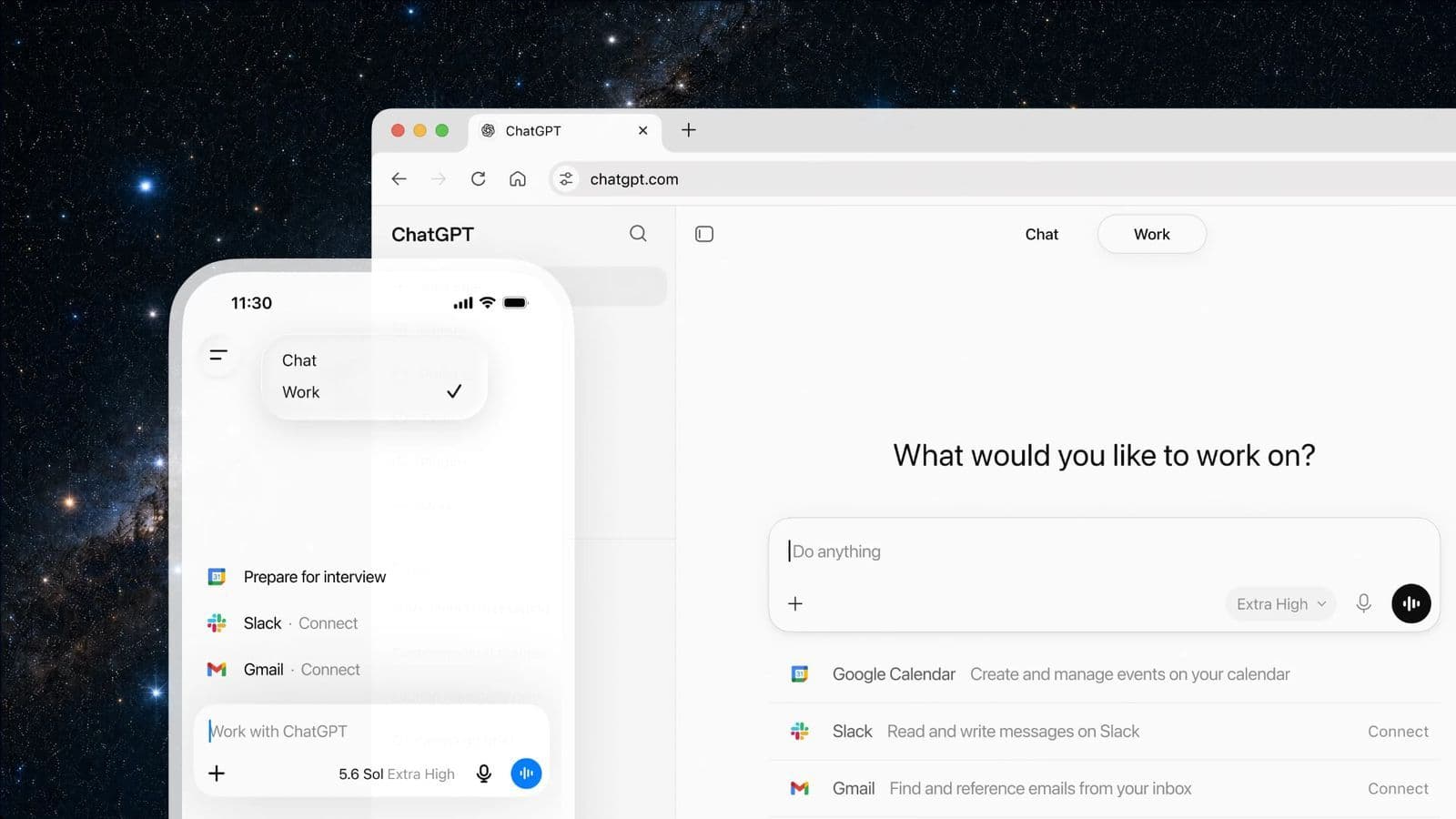
Launching alongside the model are three platform-level additions: dynamic workflows in Claude Code, an effort control for all claude.ai and Cowork users, and a change to the Messages API that lets developers inject system entries mid-task without breaking prompt cache. Each of these changes carries more operational weight for US enterprise teams than the benchmark numbers alone.
Where it stands against GPT-5.5 and Gemini

On agentic coding, Opus 4.8 scores 69.2% on SWE-Bench Pro, compared to 64.3% for Opus 4.7, 58.6% for OpenAI's GPT-5.5, and 54.2% for Google's Gemini 3.1 Pro. For teams evaluating the best AI coding model for autonomous software work, that gap is meaningful. Multidisciplinary reasoning (Humanity's Last Exam) reaches 57.9% with tools, up from 54.7% for Opus 4.7. For agentic computer use, Opus 4.8 hits 83.4% on OSWorld-Verified, ahead of GPT-5.5 at 78.7%.
Early testers at Cursor confirmed that on their internal CursorBench, Opus 4.8 exceeds prior Opus models at every effort level, with more efficient tool calling and fewer steps per task. Devin's team noted improvements over Opus 4.6 and fixes to the comment verbosity and tool-calling issues that affected Opus 4.7. On Hebbia's financial document workflows, the upgrade delivers better citation precision and measurably more token-efficient retrieval.
Dynamic workflows and the Claude Code agent upgrade

The most consequential addition in this release cycle is not the model itself but dynamic workflows, launching in research preview for Claude Code. The feature lets Claude plan a task, then dynamically write orchestration scripts that spawn tens to hundreds of parallel subagents in a single session. Each subagent's output is independently verified before folding into the final result, so the Claude Code agent can handle work that no single pass could complete - codebase-wide security audits, framework migrations touching thousands of files, and adversarially reviewed critical work.
A concrete example from the announcement: Jarred Sumner used dynamic workflows to port the Bun runtime from Zig to Rust - approximately 750,000 lines of Rust - with 99.8% of the existing test suite passing and eleven days from first commit to merge. Work that would normally be a quarter-long project ran in under two weeks, largely unattended.
Dynamic workflows are available today for Max, Team, and Enterprise Claude Code users on CLI, Desktop, VS Code extension, and via the API on AWS Bedrock, Vertex AI, and Microsoft Foundry. Enterprise plans have them off by default; admins can enable in settings. Sessions using dynamic workflows consume substantially more tokens than a standard Claude Code session, so Anthropic recommends starting on a scoped task before running production workloads.
Effort control and what the fast mode repricing means

Opus 4.8 introduces user-level effort control across claude.ai and Cowork. The model defaults to high effort, which spends similar tokens to Opus 4.7's default while producing better output. Users can step up to extra (labeled xhigh in Claude Code) for difficult tasks and long async workflows, or dial down for faster responses that draw less from their rate limit.
Fast mode - which runs the model at roughly 2.5x the speed - is now priced at $10 per million input tokens and $50 per million output tokens. Fast mode on prior Opus models carried roughly a 6x cost premium over the base model. The new pricing brings that down to a 2x premium - a 3x reduction in claude fast mode cost. Rate limits in Claude Code have been raised to accommodate the higher token usage that comes with extra and max effort settings.
The honesty gap it closes
One of the more substantive improvements in Opus 4.8 is around honesty in agentic work. AI models generally have a tendency to report progress confidently even when evidence is thin - claiming a task is done while leaving flaws unremarked. According to Anthropic's system card, Opus 4.8 is roughly four times less likely than Opus 4.7 to let code flaws pass without flagging them. For teams running autonomous engineering workflows, that change reduces the invisible failures that accumulate when a model quietly moves on.
Anthropic's alignment assessment concluded that Opus 4.8 reaches new highs on prosocial traits, including supporting user autonomy and acting in users' best interests. Rates of misaligned behavior - things like deception or cooperation with misuse - are substantially lower than Opus 4.7 and comparable to Claude Mythos Preview, the company's restricted frontier model.
The Mythos runway ahead

Anthropic is explicit that Opus 4.8 is not the ceiling. The company has announced a new class of model with higher intelligence than Opus is in development, and that Mythos-class models are expected to become available to all customers within weeks. The qualifier is safety infrastructure: Project Glasswing, the restricted cybersecurity initiative running Claude Mythos Preview across more than 50 partner organizations including AWS, Google, Microsoft, and CrowdStrike, has already identified more than 10,000 high or critical-severity software vulnerabilities. The program is actively developing the safeguards required for a broader Mythos release.
For US enterprise teams evaluating claude code enterprise deployments and AI infrastructure planning for the second half of 2026, the practical choice today is Opus 4.8. The competitive picture against GPT-5.5 and Gemini 3.1 Pro is favorable at the same price point. The dynamic workflows capability has no direct equivalent at this tier from any major competitor. And the Mythos general release - with its step-change capabilities - is the near-term event to position for.
Sources
Brian Weerasinghe is the founder and editor of AI Eating The World, where he covers artificial intelligence, tech companies, layoffs, startups, and the future of work. His reporting focuses on how AI is transforming businesses, products, and the global workforce. He writes about major developments across the AI industry, from enterprise adoption and funding trends to the real-world impact of automation and emerging technologies.